Coding in Python: Dos and Don’ts#
To Code or Not to Code?#
Before you start implementing functions which then go into the climada code base, you have to ask yourself a few questions:
Has something similar already been implemented?
This is far from trivial to answer!
First, search for functions in the same module where you’d be implementing the new piece of code.
Then, search in the util folders, there’s a lot of functions in some of the scripts!
You could also search the index (a list of all functions and global constants) in the climada documentation for key-words that may be indicative of the functionality you’re looking for.
Don’t expect this process to be fast!
Even if you want to implement just a small helper function, which might take 10mins to write, it may take you 30mins to check the existing code base! That’s part of the game!
Even if you found something, most likely, it’s not the exact same thing which you had in mind. Then, ask yourself how you can re-use what’s there, or whether you can easily add another option to the existing method to also fit your case, and only if it’s nearly impossible or highly unreadable to do so, write your own implementation.
Can my code serve others?
You probably have a very specific problem in mind. Yet, think about other use-cases, where people may have a similar problem, and try to either directly account for those, or at least make it easy to configure to other cases. Providing keyword options and hard-coding as few things as possible is usually a good thing. For example, if you want to write a daily aggregation function for some time-series, consider that other people might find it useful to have a general function that can also aggregate by week, month or year.
Can I get started?
Before you finally start coding, be sure about placing them in a sensible location. Functions in non-util modules are actually specific for that module (e.g. a file-reader function is probably not river-flood specific, so put it into the util section, not the RiverFlood module, even if that’s what you’re currently working on)!
If unsure, talk with other people about where your code should go.
If you’re implementing more than just a function or two, or even an entirely new module, the planning process should be talked over with someone doing climada-administration.
Clean Code#
A few basic principles:
Follow the PEP 8 Style Guide. It contains, among others, recommendations on:
code layout
basic naming conventions
programming recommendations
commenting (in detail described in Chapter 4)
varia
Perform a static code analysis - or: PyLint is your friend
Follow the best practices of Correctness - Tightness - Readability
Adhere to principles of pythonic coding (idiomatic coding, the “python way”)

PEP 8 Quickie: Code Layout#
Indentation: 4 spaces per level. For continuation lines, decide between vertical alignment & hanging indentation as shown here:
# Vertically aligned with opening delimiter.
foo = long_function_name(var_one, var_two, var_three, var_four)
# Hanging indentation (4 additonal spaces)
def very_very_long_function_name(var_one, var_two, var_three, var_four):
print(var_one)
Line limit: maximum of 79 characters (docstrings & comments 72).
Blank lines:
Two: Surround top-level function and class definitions;
One: Surround Method definitions inside a class
Several: may be used (sparingly) to separate groups of related functions
None: Blank lines may be omitted between a bunch of related one-liners (e.g. a set of dummy implementations).
Whitespaces:
None immediately inside parentheses, brackets or braces; after trailing commas; for keyword assignments in functions.
Do for assignments (
i = i + 1), around comparisons (>=,==, etc.), around booleans (and,or,not)the following 3 examples are correct:
spam(ham[1], {eggs: 2})
if x == 4: print x, y; x, y = y, x
def complex(real, imag=0.0):
There’s more in the PEP 8 guide!
PEP 8 Quickie: Basic Naming Conventions#
A short typology:
b (single lowercase letter); B (single uppercase letter); lowercase; lower_case_with_underscores; UPPERCASE; UPPER_CASE_WITH_UNDERSCORES; CapitalizedWords (or CapWords, or CamelCase); mixedCase; Capitalized_Words_With_Underscores (ugly!)
A few basic rules:
packages and modules: short, all-lowercase names. Underscores can be used in the module name if it improves readability. E.g.
numpy,climadaclasses: use the CapWords convention. E.g.
RiverFloodfunctions, methods and variables: lowercase, with words separated by underscores as necessary to improve readability. E.g.
from_raster(),dst_metafunction- and method arguments: Always use
selffor the first argument to instance methods,clsfor the first argument to class methods.constants: all capital letters with underscores, e.g.
DEF_VAR_EXCEL
Use of underscores
_single_leading_underscore: weak “internal use” indicator. E.g.from M import *does not import objects whose names start with an underscore. A side-note to this: Always decide whether a class’s methods and instance variables (collectively: “attributes”) should be public or non-public. If in doubt, choose non-public; it’s easier to make it public later than to make a public attribute non-public. Public attributes are those that you expect unrelated clients of your class to use, with your commitment to avoid backwards incompatible changes. Non-public attributes are those that are not intended to be used by third parties; you make no guarantees that non-public attributes won’t change or even be removed. Public attributes should have no leading underscores.single_trailing_underscore_: used by convention to avoid conflicts with Python keyword, e.g.tkinter.Toplevel(master, class_='ClassName')__double_leading_and_trailing_underscore__: “magic” objects or attributes that live in user-controlled namespaces. E.g.__init__,__import__or__file__. Never invent such names; only use them as documented.
There are many more naming conventions, some a bit messy. Have a look at the PEP8 style guide for more cases.
PEP 8 Quickie: Programming Recommendations#
comparisons to singletons like
Noneshould always be done withisoris not, never the equality operators.Use
is notoperator rather thannot ... is.
Be consistent in return statements. Either all return statements in a function should return an expression, or none of them should. Any return statements where no value is returned should explicitly state this as
return None.
# Correct
def foo(x):
if x >= 0:
return math.sqrt(x)
else:
return None
# Wrong
def foo(x):
if x >= 0:
return math.sqrt(x)
Object type comparisons should always use isinstance() instead of comparing types directly:
# Correct:
if isinstance(obj, int):
# Wrong:
if type(obj) is type(1)
Remember: sequences (strings, lists, tuples) are false if empty; this can be used:
# Correct:
if not seq:
if seq:
# Wrong:
if len(seq):
if not len(seq)
Don’t compare boolean values to True or False using
==:
# Correct:
if greeting:
# Wrong:
if greeting == True:
Use ‘’.startswith() and ‘’.endswith() instead of string slicing to check for prefixes or suffixes.
# Correct:
if foo.startswith('bar'):
# Wrong:
if foo[:3] == 'bar':
Context managers exist and can be useful (mainly for opening and closing files
Static Code Analysis and PyLint#
Static code analysis detects style issues, bad practices, potential bugs, and other quality problems in your code, all without having to actually execute it. In Spyder, this is powered by the best in class Pylint back-end, which can intelligently detect an enormous and customizable range of problem signatures. It follows the style recommended by PEP 8 and also includes the following features:
Checking the length of each line, checking that variable names are well-formed according to the project’s coding standard, checking that declared interfaces are truly implemented.
A detailed instruction can be found here.
In brief:
In the editor, select the Code Analysis pane (if not visible, go to View -> Panes -> Code Analysis) and the file you want to be analyzed; hit the Analyze button.
The output will look somewhat similar to that:
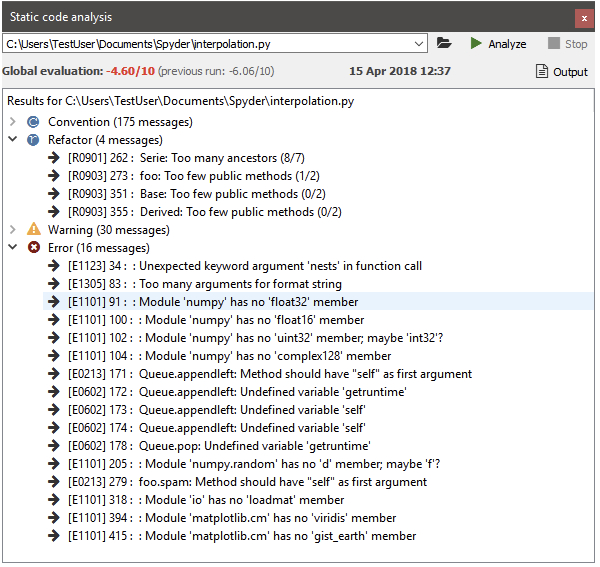
There are 4 categories in the analysis output:
convention,
refactor,
warning,
error
a global score regarding code quality.
All messages have a line reference and a short description on the issue. Errors must be fixed, as this is a no-go for actually executing the script. Warnings and refactoring messages should be taken seriously; so should be the convention messages, even though some of the naming conventions etc. may not fit the project style. This is configurable.
In general, there should be no errors and warnings left, and the overall code quality should be in the “green” range (somewhere above 5 or so).
There are advanced options to configure the type of warnings and other settings in pylint.
A few more best practices#
Correctness
Methods and functions must return correct and verifiable results, not only under the best circumstances but in any possible context. I.e. ideally there should be unit tests exploring the full space of parameters, configuration and data states. This is often clearly a non-achievable goal, but still - we aim at it.
Tightness
Avoid code redundancy.
Make the program efficient, use profiling tools for detection of bottlenecks.
Try to minimize memory consumption.
Don’t introduce new dependencies (library imports) when the desired functionality is already covered by existing dependencies.
Stick to already supported file types.
Readability
Write complete Python Docstrings.
Use meaningful method and parameter names, and always annotate the data types of parameters and return values.
No context-dependent return types! Also: Avoid
Noneas return type, rather raise an Exception instead.Be generous with defining Exception classes.
Comment! Comments are welcome to be redundant. And whenever there is a particular reason for the way something is done, comment on it! See below for more detail.
For functions which implement mathematical/scientific concepts, add the actual mathematical formula as comment or to the Doctstrings. This will help maintain a high level of scientific accuracy. E.g. How is are the random walk tracks computed for tropical cyclones?
Pythonic Code#
In Python, there are certain structures that are specific to the language, or at least the syntax of how to use them. This is usually referred to as “pythonic” code.
There is an extensive overview on on crucial “pythonic” structures and methods in the Python 101 library.
A few important examples are:
iterables such as dictionaries, tuples, lists
iterators and generators (a very useful construct when it comes to code performance, as the implementation of generators avoids reading into memory huge iterables at once, and allows to read them lazily on-the-go; see this blog post for more details)
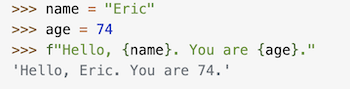
f-strings (“formatted string literals,” have an f at the beginning and curly braces containing expressions that will be replaced with their values:
decorators (a design pattern in Python that allows a user to add new functionality to an existing object without modifying its structure). Something like:
@uppercase_decorator
def say_hi():
return "hello there"
type checking (Python is a dynamically typed language; also: cf. “Duck typing”. Yet, as a best practice, variables should not change type once assigned)
Do not use mutable default arguments in your functions (e.g. lists). For example, if you define a function as such:
def function(x, list=[]): default_list.append(x)
Your list will be mutated for future calls of the functions too. The correct implementation would be the following:
def func(x, list=None): list = [] if list is None
lambda functions (little, anonymous functions,
sth likehigh_ord_func(2, lambda x: x * x))list comprehensions (a short and possibly elegant syntax to create a new list in one line,
sth likenewlist = [x for x in range(10) if x < 5]returns[0, 1, 2, 3, 4])
It is recommended to look up the above concepts in case not familiar with them.
Commenting & Documenting#
What is what#
Comments are for developers. They describe parts of the code where necessary to facilitate the understanding of programmers. They are marked by putting a # in front of every comment line (for multi-liners, wrapping them inside triple double quotes """ is basically possible, but discouraged to not mess up with docstrings).
A documentation string (docstring) is a string that describes a module, function, class, or method definition. The docstring is a special attribute of the object (object.__doc__) and, for consistency, is surrounded by triple double
quotes ("""). This is also where elaboration of the scientific foundation (explanation of used formulae, etc.) should be documented.
A few general rules:
Have a look at this blog-post on commenting basics
Comments should be D.R.Y (“Don’t Repeat Yourself.”)
Obvious naming conventions can avoid unnecessary comments (cf.
families_by_city[city]vs.my_dict[p])comments should rarely be longer than the code they support
All public methods need a doc-string. See below for details on the convention used within the climada project.
Non-public methods that are not immediately obvious to the reader should at least have a short comment after the def line:

Numpy-style docstrings#
Full reference can be found here. The standards are such that they use re-structured text (reST) syntax and are rendered using Sphinx.
There are several sections in a docstring, with headings underlined by hyphens (---). The sections of a function’s docstring are:
Short summary:
A one-line summary that does not use variable names or the function name
Deprecation warning (use if applicable):
to warn users that the object is deprecated, including version the object that was deprecated, and when it will be removed, reason for deprecation, new recommended way of obtaining the same functionality. Use thedeprecatedSphinx directive:
Extended Summary:
A few sentences giving an extended description to clarify functionality, not to discuss implementation detail or background theory (seeNotessection below!)Parameters:
 Description of the function arguments, keywords and their respective types.
Description of the function arguments, keywords and their respective types.
Enclose variables in single backticks in the description. The colon must be preceded by a space, or omitted if the type is absent.
For the parameter types, be as precise as possible.
If it is not necessary to specify a keyword argument, useoptionalafter the type specification: e.g.x: int, optional. Default values of optional parameters can also be detailed in the description. (e.g.... description of parameter ... (default is -1))
Returns:
Explanation of the returned values and their types. Similar to the Parameters section, except the name of each return value is optional, type isn’t. If both the name and type are specified, the Returns section takes the same form as the Parameters section.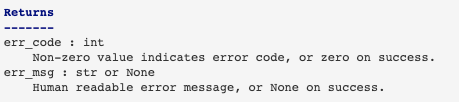
There is a range of other sections that can be included, if sensible and applicable, such as Yield (for generator functions only), Raises (which errors get raised and under what conditions), See also ( refer to related code), Notes (additional information about the code, possibly including a discussion of the algorithm; may include mathematical equations, written in LaTeX format), References, Examples(to illustrate usage).
Importing#
General remarks
Imports should be grouped in the following order:
Standard library imports (such as
re,math,datetime, cf. here )Related third party imports (such as
numpy)Local application/library specific imports (such as
climada.hazard.base)
You should put a blank line between each group of imports.
Don’t introduce new dependencies (library imports) when the desired functionality is already covered by existing dependencies.
Avoid circular importing!!
Circular imports are a form of circular dependencies that are created with the import statement in Python; e.g. module A loads a method in module B, which in turn requires loading module A. This can generate problems such as tight coupling between modules, reduced code reusability, more difficult maintenance. Circular dependencies can be the source of potential failures, such as infinite recursions, memory leaks, and cascade effects.
Generally, they can be resolved with better code design.
Have a look here for tips to identify and resolve such imports.
Varia
there are absolute imports (uses the full path starting from the project’s root folder) and relative imports (uses the path starting from the current module to the desired module; usually in the for
from .<module/package> import X; dots.indicate how many directories upwards to traverse. A single dot corresponds to the current directory; two dots indicate one folder up; etc.)generally try to avoid star imports (e.g.
from packagename import *)
Importing utility functions
When importing CLIMADA utility functions (from climada.util), the convention is to import the function as “u_name_of_function”, e.g.:
from climada.util import coordinates as u_coord
u_coord.make_map()
How to structure a method or function#
To clarify ahead: The questions of how to structure an entire module, or even “just” a class, are not treated here. For this, please get in contact with the repository admins to help you go devise a plan.
The following few principles should be adhered to when designing a function or method (which is simply the term for a function inside a class):
have a look at this blog-post summarizing a few important points to define your function (key-words abstraction, reusability, modularity)
separate algorithmic computations and data curation
adhere to a maximum method length (rule of thumb: if it doesn’t fit your screen, it’s probably an indicator that you should refactor into sub-functions)
divide functions into single purpose pieces (one function, one goal)
Debugging#
When writing code, you will encounter bugs and hence go through (more or less painful) debugging. Depending on the IDE you use, there are different debugging tools that will make your life much easier. They offer functionalities such as stopping the execution of the function just before the bug occurs (via breakpoints), allowing to explore the state of defined variables at this moment of time.
For spyder specifically, have a look at the instructions on how to use ipdb