How to use polygons or lines as exposure¶
Exposure in CLIMADA are usually represented as individual points or a raster of points. See Exposures tutorial to learn how to fill and use exposures. In this tutorial we show you how to use CLIMADA if you have your exposure in the form of shapes/polygons or in the form of lines.
The approach follows three steps: 1. transform your polygon or line in a set of points 2. do the impact calculation in CLIMADA with that set of points 3. transform the calculated Impact back to your polygon or line
Polygons¶
Polygons or shapes are a common geographical representation of countries, states etc. as for example in NaturalEarth. Here we want to show you how to deal with exposure information as polygons.
Lets assume we have the following data given. The polygons of the admin-1 regions of the netherlands and an exposure value each. We want to know the Impact of Lothar on each admin-1 region.
[5]:
from cartopy.io import shapereader
from climada.entity.exposures.black_marble import country_iso_geom
# open the file containing the Netherlands admin-1 polygons
shp_file = shapereader.natural_earth(resolution='10m',
category='cultural',
name='admin_0_countries')
shp_file = shapereader.Reader(shp_file)
# extract the NL polygons
prov_names = {'Netherlands': ['Groningen', 'Drenthe',
'Overijssel', 'Gelderland',
'Limburg', 'Zeeland',
'Noord-Brabant', 'Zuid-Holland',
'Noord-Holland', 'Friesland',
'Flevoland', 'Utrecht']
}
polygon_Netherlands, polygons_prov_NL = country_iso_geom(prov_names,
shp_file)
# assign a value to each admin-1 area (assumption 100'000 USD per inhabitant)
population_prov_NL = {'Drenthe':493449, 'Flevoland':422202,
'Friesland':649988, 'Gelderland':2084478,
'Groningen':585881, 'Limburg':1118223,
'Noord-Brabant':2562566, 'Noord-Holland':2877909,
'Overijssel':1162215, 'Zuid-Holland':3705625,
'Utrecht':1353596, 'Zeeland':383689}
value_prov_NL = {n: 100000 * population_prov_NL[n] for n in population_prov_NL.keys()}
Assume a uniform distribution of values within your polygons¶
This helps you in the case you have a given total exposure value per polygon and we assume this value is distributed evenly within the polygon.
We can now perform the three steps for this example:
[9]:
import numpy as np
from pandas import DataFrame
from climada.entity import Exposures
from climada.util.coordinates import coord_on_land
### 1. transform your polygon or line in a set of points
# create exposure with points
exp_df = DataFrame()
n_exp = 200*200
lat, lon = np.mgrid[50 : 54 : complex(0, np.sqrt(n_exp)),
3 : 8 : complex(0, np.sqrt(n_exp))]
exp_df['latitude'] = lat.flatten() # provide latitude
exp_df['longitude'] = lon.flatten() # provide longitude
exp_df['if_WS'] = np.ones(n_exp, int) # provide impact functions
# now we assign each point a province and a value, if the points are within one of the polygons defined above
exp_df['province'] = ''
exp_df['value'] = np.ones((exp_df.shape[0],))*np.nan
for prov_name_i, prob_polygon_i in zip(prov_names['Netherlands'],polygons_prov_NL['NLD']):
in_geom = coord_on_land(lat=exp_df['latitude'],
lon=exp_df['longitude'],
land_geom=prob_polygon_i)
np.put(exp_df['province'].values, np.where(in_geom)[0], prov_name_i)
np.put(exp_df['value'].values, np.where(in_geom)[0], value_prov_NL[prov_name_i]/sum(in_geom))
exp_df = Exposures(exp_df)
exp_df.set_geometry_points() # set geometry attribute (shapely Points) from GeoDataFrame from latitude and longitude
exp_df.check()
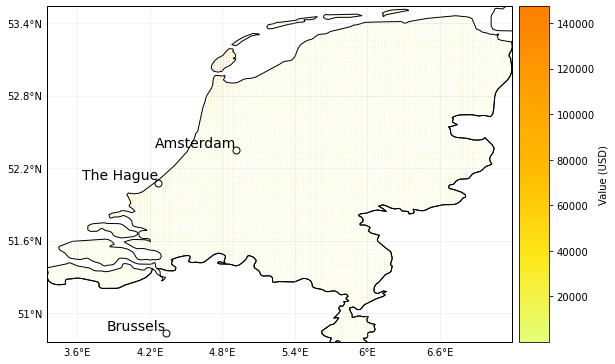
exp_df.plot_hexbin()
2021-02-08 17:21:47,679 - climada.entity.exposures.base - INFO - meta set to default value {}
2021-02-08 17:21:47,680 - climada.entity.exposures.base - INFO - tag set to default value File:
Description:
2021-02-08 17:21:47,681 - climada.entity.exposures.base - INFO - ref_year set to default value 2018
2021-02-08 17:21:47,681 - climada.entity.exposures.base - INFO - value_unit set to default value USD
2021-02-08 17:21:47,682 - climada.entity.exposures.base - INFO - crs set to default value: {'init': 'epsg:4326', 'no_defs': True}
2021-02-08 17:21:47,683 - climada.util.coordinates - INFO - Setting geometry points.
2021-02-08 17:21:49,241 - climada.entity.exposures.base - INFO - centr_ not set.
2021-02-08 17:21:49,242 - climada.entity.exposures.base - INFO - deductible not set.
2021-02-08 17:21:49,243 - climada.entity.exposures.base - INFO - cover not set.
2021-02-08 17:21:49,243 - climada.entity.exposures.base - INFO - category_id not set.
2021-02-08 17:21:49,244 - climada.entity.exposures.base - INFO - region_id not set.
[9]:
<cartopy.mpl.geoaxes.GeoAxesSubplot at 0x7fdd0852f9d0>
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/cartopy/mpl/feature_artist.py:225: MatplotlibDeprecationWarning: Using a string of single character colors as a color sequence is deprecated. Use an explicit list instead.
**dict(style))

[10]:
from climada.hazard.storm_europe import StormEurope
from climada.util.constants import WS_DEMO_NC
from climada.entity.impact_funcs.storm_europe import IFStormEurope
from climada.entity.impact_funcs import ImpactFuncSet
from climada.engine import Impact
### 2. do the impact calculation in CLIMADA with that set of points
# define hazard
storms = StormEurope()
storms.read_footprints(WS_DEMO_NC, description='test_description')
# define impact function
impact_func = IFStormEurope()
impact_func.set_welker()
impact_function_set = ImpactFuncSet()
impact_function_set.append(impact_func)
# calculate hazard
impact_NL = Impact()
impact_NL.calc(exp_df, impact_function_set, storms, save_mat=True)
impact_NL.plot_hexbin_impact_exposure()
2021-02-08 17:23:17,646 - climada.hazard.storm_europe - INFO - Constructing centroids from /Users/ckropf/climada/demo/data/fp_lothar_crop-test.nc
2021-02-08 17:23:17,664 - climada.hazard.centroids.centr - INFO - Convert centroids to GeoSeries of Point shapes.
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/pyproj/crs/crs.py:53: FutureWarning: '+init=<authority>:<code>' syntax is deprecated. '<authority>:<code>' is the preferred initialization method. When making the change, be mindful of axis order changes: https://pyproj4.github.io/pyproj/stable/gotchas.html#axis-order-changes-in-proj-6
return _prepare_from_string(" ".join(pjargs))
2021-02-08 17:23:19,496 - climada.hazard.storm_europe - INFO - Commencing to iterate over netCDF files.
2021-02-08 17:23:19,565 - climada.entity.exposures.base - INFO - Matching 40000 exposures with 9944 centroids.
2021-02-08 17:23:22,025 - climada.engine.impact - INFO - Calculating damage for 9660 assets (>0) and 2 events.
/Users/ckropf/Documents/Climada/climada_python/climada/util/plot.py:314: UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations.
fig.tight_layout()
[10]:
<cartopy.mpl.geoaxes.GeoAxesSubplot at 0x7fdd0857c490>
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/cartopy/mpl/feature_artist.py:225: MatplotlibDeprecationWarning: Using a string of single character colors as a color sequence is deprecated. Use an explicit list instead.
**dict(style))
[12]:
import pandas as pd
### 3. transform the calculated Impact back to your polygon or line
impact_at_province_raw = pd.DataFrame(np.mean(impact_NL.imp_mat.todense().transpose(), axis=1),
index=exp_df.gdf['province'])
impact_at_province = impact_at_province_raw.groupby(impact_at_province_raw.index).sum()
print(impact_at_province)
0
province
0.000000e+00
Drenthe 6.852537e+04
Flevoland 2.716078e+05
Friesland 7.782136e+05
Gelderland 4.056456e+05
Groningen 1.150089e+05
Limburg 2.559739e+05
Noord-Brabant 7.391625e+05
Noord-Holland 5.908293e+06
Overijssel 1.588620e+05
Utrecht 4.846288e+05
Zeeland 4.069767e+05
Zuid-Holland 2.893966e+06
Use the LitPop module to disaggregate your exposure values¶
Instead of a uniform distribution, another geographical distribution can be chosen to disaggregate within the value within each polygon. We show here the example of LitPop. The same three steps apply:
[16]:
import numpy as np
from climada.entity import LitPop
from climada.util.coordinates import coord_on_land
### 1. transform your polygon or line in a set of points
# create exposure with points
exp_df_lp = LitPop()
exp_df_lp.set_country('Netherlands',res_arcsec = 60, fin_mode = 'none')
exp_df_lp.gdf['if_WS'] = np.ones(exp_df_lp.gdf.shape[0], int) # provide impact functions
# now we assign each point a province and a value, if the points are within one of the polygons defined above
exp_df_lp.gdf['province'] = ''
for prov_name_i, prob_polygon_i in zip(prov_names['Netherlands'],polygons_prov_NL['NLD']):
in_geom = coord_on_land(lat=exp_df_lp.gdf['latitude'],
lon=exp_df_lp.gdf['longitude'],
land_geom=prob_polygon_i)
np.put(exp_df_lp.gdf['province'].values, np.where(in_geom)[0], prov_name_i)
exp_df_lp.gdf['value'][np.where(in_geom)[0]] = \
exp_df_lp.gdf['value'][np.where(in_geom)[0]] * value_prov_NL[prov_name_i]/sum(exp_df_lp.gdf['value'][np.where(in_geom)[0]])
exp_df_lp.gdf = exp_df_lp.gdf.drop(np.where(exp_df_lp.gdf['province']=='')[0]) #drop carribean islands for this example
exp_df_lp.set_geometry_points()
exp_df_lp.check()
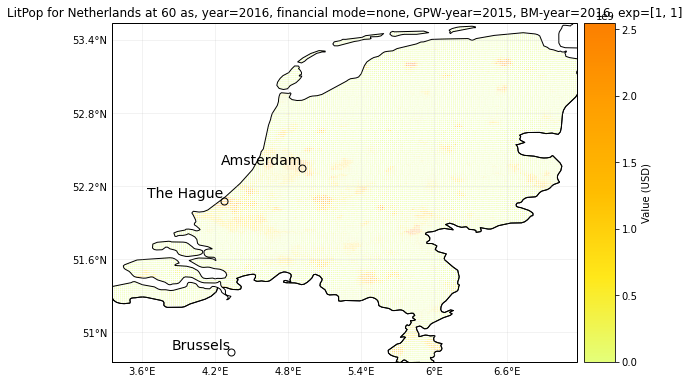
exp_df_lp.plot_hexbin()
2021-02-08 17:27:21,312 - climada.util.coordinates - INFO - Setting geometry points.
2021-02-08 17:27:22,390 - climada.entity.exposures.base - INFO - Hazard type not set in if_
2021-02-08 17:27:22,391 - climada.entity.exposures.base - INFO - centr_ not set.
2021-02-08 17:27:22,392 - climada.entity.exposures.base - INFO - deductible not set.
2021-02-08 17:27:22,393 - climada.entity.exposures.base - INFO - cover not set.
2021-02-08 17:27:22,394 - climada.entity.exposures.base - INFO - category_id not set.
/Users/ckropf/Documents/Climada/climada_python/climada/util/plot.py:314: UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations.
fig.tight_layout()
[16]:
<cartopy.mpl.geoaxes.GeoAxesSubplot at 0x7fdd08558250>
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/cartopy/mpl/feature_artist.py:225: MatplotlibDeprecationWarning: Using a string of single character colors as a color sequence is deprecated. Use an explicit list instead.
**dict(style))
[17]:
from climada.hazard.storm_europe import StormEurope
from climada.util.constants import WS_DEMO_NC
from climada.entity.impact_funcs.storm_europe import IFStormEurope
from climada.entity.impact_funcs import ImpactFuncSet
from climada.engine import Impact
### 2. do the impact calculation in CLIMADA with that set of points
# define hazard
storms = StormEurope()
storms.read_footprints(WS_DEMO_NC, description='test_description')
# define impact function
impact_func = IFStormEurope()
impact_func.set_welker()
impact_function_set = ImpactFuncSet()
impact_function_set.append(impact_func)
# calculate hazard
impact_NL = Impact()
impact_NL.calc(exp_df_lp, impact_function_set, storms, save_mat=True)
impact_NL.plot_hexbin_impact_exposure()
2021-02-08 17:27:53,235 - climada.hazard.storm_europe - INFO - Constructing centroids from /Users/ckropf/climada/demo/data/fp_lothar_crop-test.nc
2021-02-08 17:27:53,427 - climada.hazard.centroids.centr - INFO - Convert centroids to GeoSeries of Point shapes.
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/pyproj/crs/crs.py:53: FutureWarning: '+init=<authority>:<code>' syntax is deprecated. '<authority>:<code>' is the preferred initialization method. When making the change, be mindful of axis order changes: https://pyproj4.github.io/pyproj/stable/gotchas.html#axis-order-changes-in-proj-6
return _prepare_from_string(" ".join(pjargs))
2021-02-08 17:27:55,697 - climada.hazard.storm_europe - INFO - Commencing to iterate over netCDF files.
2021-02-08 17:27:55,807 - climada.entity.exposures.base - INFO - Matching 17576 exposures with 9944 centroids.
2021-02-08 17:27:56,842 - climada.engine.impact - INFO - Calculating damage for 16834 assets (>0) and 2 events.
/Users/ckropf/Documents/Climada/climada_python/climada/util/plot.py:314: UserWarning: Tight layout not applied. The left and right margins cannot be made large enough to accommodate all axes decorations.
fig.tight_layout()
[17]:
<cartopy.mpl.geoaxes.GeoAxesSubplot at 0x7fdcf5ceb650>
/Users/ckropf/opt/anaconda3/envs/climada_uncertainty/lib/python3.7/site-packages/cartopy/mpl/feature_artist.py:225: MatplotlibDeprecationWarning: Using a string of single character colors as a color sequence is deprecated. Use an explicit list instead.
**dict(style))

[20]:
import pandas as pd
### 3. transform the calculated Impact back to your polygon or line
impact_at_province_raw = pd.DataFrame(np.mean(impact_NL.imp_mat.todense().transpose(), axis=1),
index=exp_df_lp.gdf['province'])
impact_at_province_lp = impact_at_province_raw.groupby(impact_at_province_raw.index).sum()
print(impact_at_province_lp)
0
province
Drenthe 6.397671e+04
Flevoland 1.666099e+05
Friesland 4.602394e+05
Gelderland 3.284452e+05
Groningen 1.563104e+05
Limburg 3.730663e+05
Noord-Brabant 6.247242e+05
Noord-Holland 1.819026e+06
Overijssel 1.074240e+05
Utrecht 4.484917e+05
Zeeland 7.632003e+05
Zuid-Holland 2.898284e+06
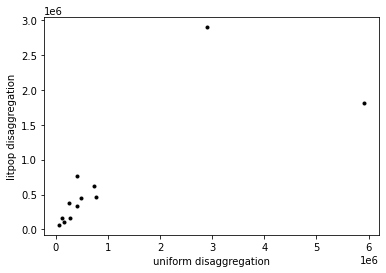
Comparison of both modelled impacts:
[21]:
from matplotlib import pyplot as plt
plt.plot(impact_at_province[impact_at_province.index!=''],impact_at_province_lp, '.k')
plt.xlabel('uniform disaggregation')
plt.ylabel('litpop disaggregation')
[21]:
Text(0, 0.5, 'litpop disaggregation')
Further statistical analysis of hazard on polygon level¶
imagine that you need access to the hazard centroids in oder to provide some statistical analysis on the province level
[26]:
%%time
# this provides the wind speed value for each event at the corresponding exposure
import scipy
exp_df_lp.gdf[:5]
l1,l2,vals = scipy.sparse.find(storms.intensity)
exp_df_lp.gdf['wind_0']=0; exp_df_lp.gdf['wind_1']=0 # provide columns for both events
for evt,idx,val in zip(l1,l2,vals):
if evt==0:
exp_df_lp.gdf.loc[exp_df_lp.gdf.index[exp_df_lp.gdf['centr_WS']==idx],'wind_0']=val
else:
exp_df_lp.gdf.loc[exp_df_lp.gdf.index[exp_df_lp.gdf['centr_WS']==idx],'wind_1']=val
CPU times: user 14.8 s, sys: 147 ms, total: 15 s
Wall time: 15.1 s
[28]:
# now you can perform additional statistical analysis and aggregate it to the province level
import pandas as pd
import geopandas as gpd
exp_province_raw = exp_df_lp.copy()
def f(x): # define function for statistical aggregation with pandas
d = {}
d['value'] = x['value'].sum()
d['wind_0'] = x['wind_0'].max()
d['wind_1'] = x['wind_1'].mean()
# one could also be interested in centroid of max wind with respect to province
#d['centr_WS'] = x.loc[x.index[x['wind_0'].max()],'centr_WS']
return pd.Series(d, index=['value', 'wind_0', 'wind_1'])
exp_province = exp_province_raw.gdf.groupby('province').apply(f).reset_index() # Result is not a GeoDataFrame anymore
# add geometries to DataFrame and plot results
exp_province=gpd.GeoDataFrame(exp_province, geometry=None)
for prov,poly in zip(list(prov_names.values())[0],polygons_prov_NL['NLD']):
exp_province.loc[exp_province.index[exp_province['province']== prov],'geometry']= gpd.GeoDataFrame(geometry=[poly]).geometry.values
exp_province
print('Plot maximum wind per province for first event')
exp_province.plot(column='wind_0', cmap='Reds', legend=True)
plt.show()
print('Plot mean wind per province for second event')
exp_province.plot(column='wind_1', cmap='Reds', legend=True)
plt.show()
Plot maximum wind per province for first event

Plot mean wind per province for second event

Lines¶
Lines are common geographical representation of transport infrastructure like streets, train tracks or powerlines etc.
[ ]:
# under construction. here follows an example on how to deal with lines