CLIMADA overview#
Introduction#
What is CLIMADA?#
CLIMADA is a fully probabilistic climate risk assessment tool. It provides a framework for users to combine exposure, hazard and vulnerability or impact data to calculate risk. Users can create probabilistic impact data from event sets, look at how climate change affects these impacts, and see how effectively adaptation measures can change them. CLIMADA also allows for studies of individual events, historical event sets and forecasts.
The model is highly customisable, meaning that users can work with out-of-the-box data provided for different hazards, population and economic exposure, or can provide their own data for part or all of the analysis. The pre-packaged data make CLIMADA particularly useful for users who focus on just one element of risk, since CLIMADA can ‘fill in the gaps’ for hazard, exposure or vulnerability in the rest of the analysis.
The model core is designed to give as much flexibility as possible when describing the elements of risk, meaning that CLIMADA isn’t limited to particular hazards, exposure types or impacts. We love to see the model applied to new problems and contexts.
CLIMADA provides classes, methods and data for exposure, hazard and impact functions (also called vulnerability functions), plus a financial model and a framework to analyse adaptation measures. Additional classes and data for common uses, such as economic exposures or tropical storms and tutorials for every class are available: see the CLIMADA features section below.
This tutorial#
This tutorial is for people new to CLIMADA who want to get a high level understanding of the model and work through an example risk analysis. It will list the current features of the model, and go through a complete CLIMADA analysis to give an idea of how the model works. Other tutorials go into more detail about different model components and individual hazards.
Resources beyond this tutorial#
Installation guide - go here if you’ve not installed the model yet
CLIMADA Read the Docs home page - for all other documentation
CLIMADA GitHub develop branch documentation for the very latest versions of code and documentation
CLIMADA paper GitHub repository - for publications using CLIMADA
CLIMADA features#
A risk analysis with CLIMADA can include
the statistical risk to your exposure from a set of events,
how it changes under climate change, and
a cost-benefit analysis of adaptation measures.
CLIMADA is flexible: the “statistical risk” above could be describing the annual expected insured flood losses to a property portfolio, the number of people displaced by an ensemble of typhoon forecasts, the annual disruption to a railway network from landslides, or changes to crop yields.
Users from risk-analysis backgrounds will be familiar with describing the impact of events by combining exposure, hazard and an impact function (or vulnerability curve) that combines the two to describe a hazard’s effects. A CLIMADA analysis uses the same approach but wraps the exposures and their impact functions into a single Entity class, along with discount rates and adaptation options (see the below tutorials for more on CLIMADA’s financial model).
CLIMADA’s Impact object is used to analyse events and event sets, whether this is the impact of a single wildfire, or the global economic risk from tropical cyclones in 2100.
CLIMADA is divided into two parts (two repositories):
the core climada_python contains all the modules necessary for the probabilistic impact, the averted damage, uncertainty and forecast calculations. Data for hazard, exposures and impact functions can be obtained from the data API. Litpop is included as demo Exposures module, and Tropical cyclones is included as a demo Hazard module.
the petals climada_petals contains all the modules for generating data (e.g., TC_Surge, WildFire, OpenStreeMap, …). Most development is done here. The petals builds-upon the core and does not work as a stand-alone.
CLIMADA classes#
This is a full directory of tutorials for CLIMADA’s classes to use as a reference. You don’t need to read all this to do this tutorial, but it may be useful to refer back to.
Core (climada_python):
Hazard: a class that stores sets of geographic hazard footprints, (e.g. for wind speed, water depth and fraction, drought index), and metadata including event frequency. Several predefined extensions to create particular hazards from particular datasets and models are included with CLIMADA:
Tropical cyclone wind: global hazard sets for tropical cyclone events, constructing statistical wind fields from storm tracks. Subclasses include methods and data to calculate historical wind footprints, create forecast enembles from ECMWF tracks, and create climatological event sets for different climate scenarios.
European windstorms: includes methods to read and plot footprints from the Copernicus WISC dataset and for DWD and ICON forecasts.
Entity: this is a container that groups CLIMADA’s socio-economic models. It’s is where the Exposures and Impact Functions are stored, which can then be combined with a hazard for a risk analysis (using the Engine’s Impact class). It is also where Discount Rates and Measure Sets are stored, which are used in adaptation cost-benefit analyses (using the Engine’s CostBenefit class):
Exposures: geolocated exposures. Each exposure is associated with a value (which can be a dollar value, population, crop yield, etc), information to associate it with impact functions for the relevant hazard(s) (in the Entity’s ImpactFuncSet), a geometry, and other optional properties such as deductables and cover. Exposures can be loaded from a file, specified by the user, or created from regional economic models accessible within CLIMADA, for example:
LitPop: regional economic model using nightlight and population maps together with several economic indicators
Polygons_lines: use CLIMADA Impf you have your exposure in the form of shapes/polygons or in the form of lines.
ImpactFuncSet: functions to describe the impacts that hazards have on exposures, expressed in terms of e.g. the % dollar value of a building lost as a function of water depth, or the mortality rate for over-70s as a function of temperature. CLIMADA provides some common impact functions, or they can be user-specified. The following is an incomplete list:
ImpactFunc: a basic adjustable impact function, specified by the user
IFTropCyclone: impact functions for tropical cyclone winds
IFRiverFlood: impact functions for river floods
IFStormEurope: impact functions for European windstorms
DiscRates: discount rates per year
MeasureSet: a collection of Measure objects that together describe any adaptation measures being modelled. Adaptation measures are described by their cost, and how they modify exposure, hazard, and impact functions (and have have a method to do these things). Measures also include risk transfer options.
Engine: the CLIMADA Engine contains the Impact and CostBenefit classes, which are where the main model calculations are done, combining Hazard and Entity objects.
Impact: a class that stores CLIMADA’s modelled impacts and the methods to calculate them from Exposure, Impact Function and Hazard classes. The calculations include average annual impact, expected annual impact by exposure item, total impact by event, and (optionally) the impact of each event on each exposure point. Includes statistical and plotting routines for common analysis products.
Impact_data: The core functionality of the module is to read disaster impact data as downloaded from the International Disaster Database EM-DAT (www.emdat.be) and produce a CLIMADA Impact()-instance from it. The purpose is to make impact data easily available for comparison with simulated impact inside CLIMADA, e.g. for calibration purposes.
CostBenefit: a class to appraise adaptation options. It uses an Entity’s MeasureSet to calculate new Impacts based on their adjustments to hazard, exposure, and impact functions, and returns statistics and plotting routines to express cost-benefit comparisons.
Unsequa: a module for uncertainty and sensitivity analysis.
Unsequa_helper: The InputVar class provides a few helper methods to generate generic uncertainty input variables for exposures, impact function sets, hazards, and entities (including measures cost and disc rates). This tutorial complements the general tutorial on the uncertainty and sensitivity analysis module unsequa.
Forecast: This class deals with weather forecasts and uses CLIMADA ImpactCalc.impact() to forecast impacts of weather events on society. It mainly does one thing: It contains all plotting and other functionality that are specific for weather forecasts, impact forecasts and warnings.
climada_petals:
-
Storm surge: Tropical cyclone surge from linear wind-surge relationship and a bathtub model.
River flooding: global water depth hazard for flood, including methods to work with ISIMIP simulations.
Crop modelling: combines ISIMIP crop simulations and UN Food and Agrigultre Organization data. The module uses crop production as exposure, with hydrometeorological ‘hazard’ increasing or decreasing production.
Wildfire (global): This class is used to model the wildfire hazard using the historical data available and creating synthetic fires which are summarized into event years to establish a comprehensiv probabilistic risk assessment.
Landslide: This class is able to handle two different types of landslide source files (in one case, already the finished product of some model output, in the other case just a historic data collection).
TCForecast: This class extends the TCTracks class with methods to download operational ECMWF ensemble tropical storm track forecasts, read the BUFR files they’re contained in and produce a TCTracks object that can be used to generate TropCyclone hazard footprints.
Emulator:Given a database of hazard events, this module climada.hazard.emulator provides tools to subsample events (or time series of events) from that event database.
Drought (global): tutorial under development
-
-
BlackMarble: regional economic model from nightlight intensities and economic indicators (GDP, income group). Largely succeeded by LitPop.
OpenStreetMap: CLIMADA provides some ways to make use of the entire OpenStreetMap data world and to use those data within the risk modelling chain of CLIMADA as exposures.
-
-
SupplyChain: This class allows assessing indirect impacts via Input-Ouput modeling.
This list will be updated periodically along with new CLIMADA releases. To see the latest, development version of all tutorials, see the tutorials page on the CLIMADA GitHub.
Tutorial: an example risk assessment#
This example will work through a risk assessment for tropical storm wind in Puerto Rico, constructing hazard, exposure and vulnerability and combining them to create an Impact object. Everything you need for this is included in the main CLIMADA installation and additional data will be downloaded by the scripts as required.
Hazard#
Hazards are characterized by their frequency of occurrence and the geographical distribution of their intensity. The Hazard class collects events of the same hazard type (e.g. tropical cyclone, flood, drought, …) with intensity values over the same geographic centroids. They might be historical events or synthetic.
See the Hazard tutorial to learn about the Hazard class in more detail, and the CLIMADA features section of this document to explore tutorials for different hazards, including tropical cyclones, as used here.
Tropical cyclones in CLIMADA and the TropCyclone class work like any hazard, storing each event’s wind speeds at the geographic centroids specified for the class. Pre-calculated hazards can be loaded from files (see the full Hazard tutorial, but they can also be modelled from a storm track using the TCTracks class, based on a storm’s parameters at each time step. This is how we’ll construct the hazards for our example.
So before we create the hazard, we will create our storm tracks and define the geographic centroids for the locations we want to calculate hazard at.
Storm tracks#
Storm tracks are created and stored in a separate class, TCTracks. We use its method from_ibtracs_netcdf to create the tracks from the IBTRaCS storm tracks archive. In the next block we will download the full dataset, which might take a little time. However, to plot the whole dataset takes too long (see the second block), so we choose a shorter time range here to show the function. See the full TropCyclone tutorial for more detail and troubleshooting.
import numpy as np
from climada.hazard import TCTracks
import warnings # To hide the warnings
warnings.filterwarnings("ignore")
tracks = TCTracks.from_ibtracs_netcdf(
provider="usa", basin="NA"
) # Here we download the full dataset for the analysis
# afterwards (e.g. return period), but you can also use "year_range" to adjust the range of the dataset to be downloaded.
# While doing that, you need to make sure that the year 2017 is included if you want to run the blocks with the codes
# subsetting a specific tropic cyclone, which happened in 2017. (Of course, you can also change the subsetting codes.)
2022-03-21 14:31:20,322 - climada.hazard.tc_tracks - WARNING - 1122 storm events are discarded because no valid wind/pressure values have been found: 1851175N26270, 1851181N19275, 1851187N22262, 1851192N12300, 1851214N14321, ...
2022-03-21 14:31:20,345 - climada.hazard.tc_tracks - WARNING - 139 storm events are discarded because only one valid timestep has been found: 1852232N21293, 1853242N12336, 1855236N12304, 1856221N25277, 1856235N13302, ...
2022-03-21 14:31:22,766 - climada.hazard.tc_tracks - INFO - Progress: 10%
2022-03-21 14:31:25,059 - climada.hazard.tc_tracks - INFO - Progress: 20%
2022-03-21 14:31:27,491 - climada.hazard.tc_tracks - INFO - Progress: 30%
2022-03-21 14:31:30,067 - climada.hazard.tc_tracks - INFO - Progress: 40%
2022-03-21 14:31:32,415 - climada.hazard.tc_tracks - INFO - Progress: 50%
2022-03-21 14:31:34,829 - climada.hazard.tc_tracks - INFO - Progress: 60%
2022-03-21 14:31:37,482 - climada.hazard.tc_tracks - INFO - Progress: 70%
2022-03-21 14:31:39,976 - climada.hazard.tc_tracks - INFO - Progress: 80%
2022-03-21 14:31:42,307 - climada.hazard.tc_tracks - INFO - Progress: 90%
2022-03-21 14:31:44,580 - climada.hazard.tc_tracks - INFO - Progress: 100%
2022-03-21 14:31:45,780 - climada.hazard.tc_tracks - INFO - Progress: 10%
2022-03-21 14:31:45,833 - climada.hazard.tc_tracks - INFO - Progress: 21%
2022-03-21 14:31:45,886 - climada.hazard.tc_tracks - INFO - Progress: 31%
2022-03-21 14:31:45,939 - climada.hazard.tc_tracks - INFO - Progress: 42%
2022-03-21 14:31:45,992 - climada.hazard.tc_tracks - INFO - Progress: 52%
2022-03-21 14:31:46,048 - climada.hazard.tc_tracks - INFO - Progress: 63%
2022-03-21 14:31:46,100 - climada.hazard.tc_tracks - INFO - Progress: 73%
2022-03-21 14:31:46,150 - climada.hazard.tc_tracks - INFO - Progress: 84%
2022-03-21 14:31:46,203 - climada.hazard.tc_tracks - INFO - Progress: 94%
2022-03-21 14:31:46,232 - climada.hazard.tc_tracks - INFO - Progress: 100%
This will load all historical tracks in the North Atlantic into the tracks object (since we set basin='NA'). The TCTracks.plot method will plot the downloaded tracks, though there are too many for the plot to be very useful:
# plotting tracks can be very time consuming, depending on the number of tracks. So we choose only a few here, by limiting the time range to one year
tracks_2017 = TCTracks.from_ibtracs_netcdf(
provider="usa", basin="NA", year_range=(2017, 2017)
)
tracks_2017.plot(); # This may take a very long time
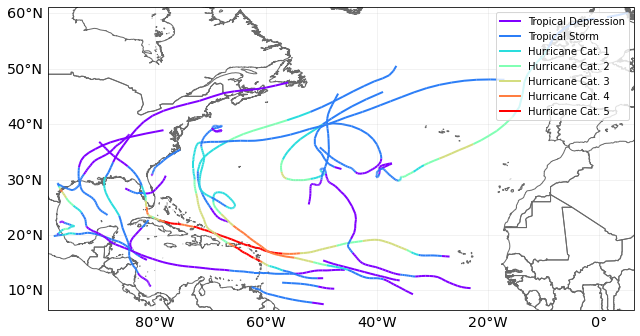
It’s also worth adding additional time steps to the tracks (though this can be memory intensive!). Most tracks are reported at 3-hourly intervals (plus a frame at landfall). Event footprints are calculated as the maximum wind from any time step. For a fast-moving storm these combined three-hourly footprints give quite a rough event footprint, and it’s worth adding extra frames to smooth the footprint artificially (try running this notebook with and without this interpolation to see the effect):
tracks.equal_timestep(time_step_h=0.5)
2022-03-21 14:32:39,466 - climada.hazard.tc_tracks - INFO - Interpolating 1049 tracks to 0.5h time steps.
Now, irresponsibly for a risk analysis, we’re only going to use these historical events: they’re enough to demonstrate CLIMADA in action. A proper risk analysis would expand it to include enough events for a statistically robust climatology. See the full TropCyclone tutorial for CLIMADA’s stochastic event generation.
Centroids#
A hazard’s centroids can be any set of locations where we want the hazard to be evaluated. This could be the same as the locations of your exposure, though commonly it is on a regular lat-lon grid (with hazard being imputed to exposure between grid points).
Here we’ll set the centroids as a 0.1 degree grid covering Puerto Rico. Centroids are defined by a Centroids class, which has the from_pnt_bounds method for generating regular grids and a plot method to inspect the centroids.
from climada.hazard import Centroids
min_lat, max_lat, min_lon, max_lon = 17.5, 19.0, -68.0, -65.0
cent = Centroids.from_pnt_bounds((min_lon, min_lat, max_lon, max_lat), res=0.05)
cent.plot();
Hazard footprint#
Now we’re ready to create our hazard object. This will be a TropCyclone class, which inherits from the Hazard class, and has the from_tracks constructor method to create a hazard from a TCTracks object at given centroids.
from climada.hazard import TropCyclone
haz = TropCyclone.from_tracks(tracks, centroids=cent)
haz.check() # verifies that the necessary data for the Hazard object is correctly provided
2022-03-21 14:35:51,458 - climada.hazard.centroids.centr - INFO - Convert centroids to GeoSeries of Point shapes.
2022-03-21 14:35:52,496 - climada.util.coordinates - INFO - dist_to_coast: UTM 32619 (1/2)
2022-03-21 14:35:53,234 - climada.util.coordinates - INFO - dist_to_coast: UTM 32620 (2/2)
2022-03-21 14:35:53,706 - climada.hazard.trop_cyclone - INFO - Mapping 1049 tracks to 1891 coastal centroids.
2022-03-21 14:35:56,704 - climada.hazard.trop_cyclone - INFO - Progress: 10%
2022-03-21 14:36:00,561 - climada.hazard.trop_cyclone - INFO - Progress: 20%
2022-03-21 14:36:05,356 - climada.hazard.trop_cyclone - INFO - Progress: 30%
2022-03-21 14:36:09,524 - climada.hazard.trop_cyclone - INFO - Progress: 40%
2022-03-21 14:36:15,423 - climada.hazard.trop_cyclone - INFO - Progress: 50%
2022-03-21 14:36:20,307 - climada.hazard.trop_cyclone - INFO - Progress: 60%
2022-03-21 14:36:25,005 - climada.hazard.trop_cyclone - INFO - Progress: 70%
2022-03-21 14:36:30,606 - climada.hazard.trop_cyclone - INFO - Progress: 80%
2022-03-21 14:36:35,743 - climada.hazard.trop_cyclone - INFO - Progress: 90%
2022-03-21 14:36:41,322 - climada.hazard.trop_cyclone - INFO - Progress: 100%
In 2017 Hurricane Maria devastated Puerto Rico. In the IBTRaCs event set, it has ID 2017260N12310 (we use this rather than the name, as IBTRaCS contains three North Atlantic storms called Maria). We can plot the track:
tracks.subset(
{"sid": "2017260N12310"}
).plot(); # This is how we subset a TCTracks object
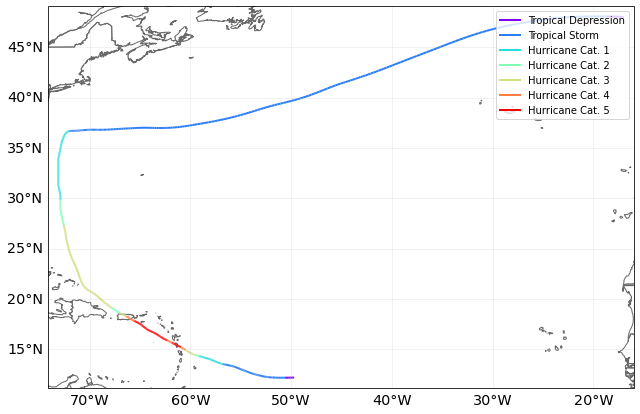
And plot the hazard on our centroids for Puerto Rico:
haz.plot_intensity(event="2017260N12310");
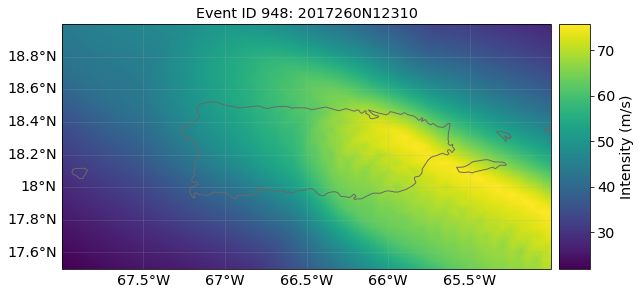
A Hazard object also lets us plot the hazard at different return periods. The IBTRaCS archive produces footprints from 1980 onwards (CLIMADA discarded earlier events) and so the historical period is short. Therefore these plots don’t make sense as ‘real’ return periods, but we’re being irresponsible and demonstrating the functionality anyway.
haz.plot_rp_intensity(return_periods=(5, 10, 20, 40));
2022-03-15 22:20:11,511 - climada.hazard.base - INFO - Computing exceedance intenstiy map for return periods: [ 5 10 20 40]
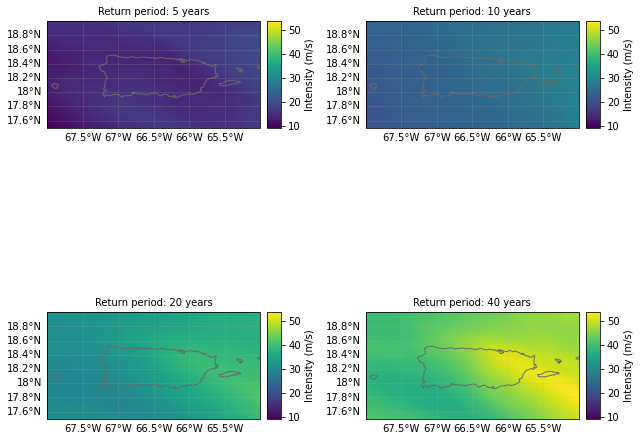
See the TropCyclone tutorial for full details of the TropCyclone hazard class.
We can also recalculate event sets to reflect the effects of climate change. The apply_climate_scenario_knu method applies changes in intensity and frequency projected due to climate change, as described in ‘Global projections of intense tropical cyclone activity for the late twenty-first century from dynamical downscaling of CMIP5/RCP4.5 scenarios’ (Knutson et al. 2015). See the tutorial for details.
Exercise: Extend this notebook’s analysis to examine the effects of climate change in Puerto Rico. You’ll need to extend the historical event set with stochastic tracks to create a robust statistical storm climatology - the
TCTracksclass has the functionality to do this. Then you can apply theapply_climate_scenario_knumethod to the generated hazard object to create a second hazard climatology representing storm activity under climate change. See how the results change using the different hazard sets.
Next we’ll work on exposure and vulnerability, part of the Entity class.
Entity#
The entity class is a container class that stores exposures and impact functions (vulnerability curves) needed for a risk calculation, and the discount rates and adaptation measures for an adaptation cost-benefit analysis.
As with Hazard objects, Entities can be read from files or created through code. The Excel template can be found in climada_python/climada/data/system/entity_template.xlsx.
In this tutorial we will create an Exposure object using the LitPop economic exposure module, and load a pre-defined wind damage function.
Exposures#
The Entity’s exposures attribute contains geolocalized values of anything exposed to the hazard, whether monetary values of assets or number of human lives, for example. It is of type Exposures.
See the Exposures tutorial for more detail on the structure of the class, and how to create and import exposures. The LitPop tutorial explains how CLIMADA models economic exposures using night-time light and economic data, and is what we’ll use here. To combine your exposure with OpenStreetMap’s data see the OSM tutorial.
LitPop is a module that allows CLIMADA to estimate exposed populations and economic assets at any point on the planet without additional information, and in a globally consistent way. Before we try it out with the next code block, we’ll need to download a data set and put it into the right folder:
Go to the download page on Socioeconomic Data and Applications Center (sedac).
You’ll be asked to log in or register. Please register if you don’t have an account.
Wait until several drop-down menus show up.
Choose in the drop-down menus: Temporal: single year, FileFormat: GeoTiff, Resolution: 30 seconds. Click “2020” and then “create download”.
Copy the file “gpw_v4_population_count_rev11_2020_30_sec.tif” into the folder “~/climada/data”. (Or you can run the block once to find the right path in the error message)
Now we can create an economic Exposure dataset for Puerto Rico.
from climada.entity.exposures import LitPop
exp_litpop = LitPop.from_countries(
"Puerto Rico", res_arcsec=120
) # We'll go lower resolution than default to keep it simple
exp_litpop.plot_hexbin(pop_name=True, linewidth=4, buffer=0.1);
2022-03-21 14:37:03,770 - climada.entity.exposures.litpop.litpop - INFO -
LitPop: Init Exposure for country: PRI (630)...
2022-03-21 14:37:03,773 - climada.entity.exposures.litpop.gpw_population - WARNING - Reference year: 2018. Using nearest available year for GPW data: 2020
2022-03-21 14:37:03,774 - climada.entity.exposures.litpop.gpw_population - INFO - GPW Version v4.11
2022-03-21 14:37:03,824 - climada.entity.exposures.litpop.nightlight - INFO - No satellite files found locally in /home/yuyue/climada/data
2022-03-21 14:37:03,826 - climada.entity.exposures.litpop.nightlight - INFO - Attempting to download file from https://eoimages.gsfc.nasa.gov/images/imagerecords/144000/144897/BlackMarble_2016_B1_geo_gray.tif
2022-03-21 14:37:04,665 - climada.util.files_handler - INFO - Downloading https://eoimages.gsfc.nasa.gov/images/imagerecords/144000/144897/BlackMarble_2016_B1_geo_gray.tif to file /home/yuyue/climada/data/BlackMarble_2016_B1_geo_gray.tif
26.8kKB [00:02, 9.72kKB/s]
2022-03-21 14:37:08,919 - climada.util.files_handler - INFO - Downloading https://databank.worldbank.org/data/download/Wealth-Accounts_CSV.zip to file /mnt/c/Users/yyljy/Documents/climada_main/doc/tutorial/results/Wealth-Accounts_CSV.zip
1.44kKB [00:03, 429KB/s]
2022-03-21 14:37:12,440 - climada.util.finance - WARNING - No data available for country. Using non-financial wealth instead
2022-03-21 14:37:13,356 - climada.util.finance - INFO - GDP PRI 2018: 1.009e+11.
2022-03-21 14:37:13,361 - climada.util.finance - WARNING - No data for country, using mean factor.
2022-03-21 14:37:13,378 - climada.entity.exposures.base - INFO - Hazard type not set in impf_
2022-03-21 14:37:13,380 - climada.entity.exposures.base - INFO - category_id not set.
2022-03-21 14:37:13,381 - climada.entity.exposures.base - INFO - cover not set.
2022-03-21 14:37:13,383 - climada.entity.exposures.base - INFO - deductible not set.
2022-03-21 14:37:13,384 - climada.entity.exposures.base - INFO - centr_ not set.
2022-03-21 14:37:13,387 - climada.util.coordinates - INFO - Setting geometry points.
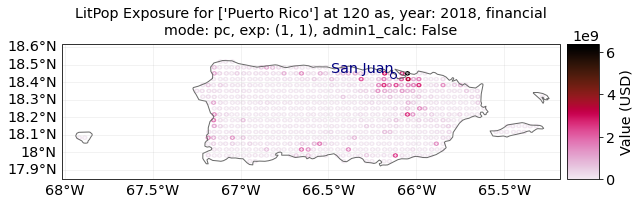
LitPop’s default exposure is measured in US Dollars, with a reference year depending on the most recent data available.
Once we’ve created our impact function we will come back to this Exposure and give it the parameters needed to connect exposure to impacts.
Impact functions#
Impact functions describe a relationship between a hazard’s intensity and your exposure in terms of a percentage loss. The impact is described through two terms. The Mean Degree of Damage (MDD) gives the percentage of an exposed asset’s numerical value that’s affected as a function of intensity, such as the damage to a building from wind in terms of its total worth. Then the Proportion of Assets Affected (PAA) gives the fraction of exposures that are affected, such as the mortality rate in a population from a heatwave. These multiply to give the Mean Damage Ratio (MDR), the average impact to an asset.
Impact functions are stored as the Entity’s impact_funcs attribute, in an instance of the ImpactFuncSet class which groups one or more ImpactFunc objects. They can be specified manually, read from a file, or you can use CLIMADA’s pre-defined impact functions. We’ll use a pre-defined function for tropical storm wind damage stored in the IFTropCyclone class.
See the Impact Functions tutorial for a full guide to the class, including how data are stored and reading and writing to files.
We initialise an Impact Function with the IFTropCyclone class, and use its from_emanuel_usa method to load the Emanuel (2011) impact function. (The class also contains regional impact functions for the full globe, but we’ll won’t use these for now.) The class’s plot method visualises the function, which we can see is expressed just through the Mean Degree of Damage, with all assets affected.
from climada.entity.impact_funcs import ImpactFuncSet, ImpfTropCyclone
imp_fun = ImpfTropCyclone.from_emanuel_usa()
imp_fun.plot();
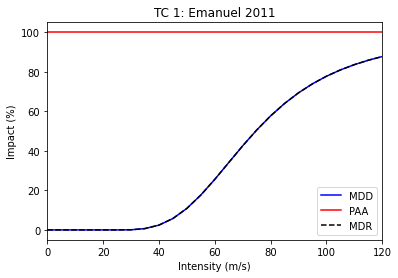
The plot title also includes information about the function’s ID, which were also set by the from_emanuel_usa class method. The hazard is “TC” and the function ID is 1. Since a study might use several impact functions - for different hazards, or for different types of exposure.
We then create an ImpactFuncSet object to store the impact function. This is a container class, and groups a study’s impact functions together. Studies will often have several impact functions, due to multiple hazards, multiple types of exposure that are impacted differently, or different adaptation scenarios. We add it to our Entity object.
imp_fun_set = ImpactFuncSet([imp_fun])
Finally, we can update our LitPop exposure to point to the TC 1 impact function. This is done by adding a column to the exposure:
exp_litpop.gdf["impf_TC"] = 1
2022-03-21 14:37:53,587 - climada.entity.exposures.base - INFO - Hazard type not set in impf_
2022-03-21 14:37:53,591 - climada.entity.exposures.base - INFO - category_id not set.
2022-03-21 14:37:53,593 - climada.entity.exposures.base - INFO - cover not set.
2022-03-21 14:37:53,594 - climada.entity.exposures.base - INFO - deductible not set.
2022-03-21 14:37:53,595 - climada.entity.exposures.base - INFO - centr_ not set.
2022-03-21 14:37:53,600 - climada.entity.impact_funcs.base - WARNING - For intensity = 0, mdd != 0 or paa != 0. Consider shifting the origin of the intensity scale. In impact.calc the impact is always null at intensity = 0.
Here the impf_TC column tells the CLIMADA engine that for a tropical cyclone (TC) hazard, it should use the first impact function defined for TCs. We use the same impact function for all of our exposure.
This is now everything we need for a risk analysis, but while we’re working on the Entity class, we can define the adaptation measures and discount rates needed for an adaptation analysis. If you’re not interested in the cost-benefit analysis, you can skip ahead to the Impact section
Adaptation measures#
CLIMADA’s adaptation measures describe possible interventions that would change event hazards and impacts, and the cost of these interventions.
They are stored as Measure objects within a MeasureSet container class (similarly to ImpactFuncSet containing several ImpactFuncs), and are assigned to the measures attribute of the Entity.
See the Adaptation Measures tutorial on how to create, read and write measures. CLIMADA doesn’t yet have pre-defined adaptation measures, mostly because they are hard to standardise.
The best way to understand an adaptation measure is by an example. Here’s a possible measure for the creation of coastal mangroves (ignore the exact numbers, they are just for illustration):
from climada.entity import Measure, MeasureSet
meas_mangrove = Measure(
name="Mangrove",
haz_type="TC",
color_rgb=np.array([0.2, 0.2, 0.7]),
cost=500000000,
mdd_impact=(1, 0),
paa_impact=(1, -0.15),
hazard_inten_imp=(1, -10),
)
meas_set = MeasureSet(measure_list=[meas_mangrove])
meas_set.check()
What values have we set here?
The
haz_typegives the hazard that this measure affects.The
costis a flat price that will be used in cost-benefit analyses.The
mdd_impact,paa_impact, andhazard_inten_impattributes are all tuples that describes a linear transformation to event hazard, the impact function’s mean damage degree and the impact function’s proportion of assets affected. The tuple(a, b)describes a scalar multiplication of the function and a constant to add. So(1, 0)is unchanged,(1.1, 0)increases values by 10%, and(1, -10)decreases all values by 10.
So the Mangrove example above costs 50,000,000 USD, protects 15% of assets from any impact at all (paa_impact = (1, -0.15)) and decreases the (effective) hazard intensity by 10 m/s (hazard_inten_imp = (1, -10).
We can apply these measures to our existing Exposure, Hazard and Impact functions, and plot the old and new impact functions:
mangrove_exp, mangrove_imp_fun_set, mangrove_haz = meas_mangrove.apply(
exp_litpop, imp_fun_set, haz
)
axes1 = imp_fun_set.plot()
axes1.set_title("TC: Emanuel (2011) impact function")
axes2 = mangrove_imp_fun_set.plot()
axes2.set_title("TC: Modified impact function")
Text(0.5, 1.0, 'TC: Modified impact function')
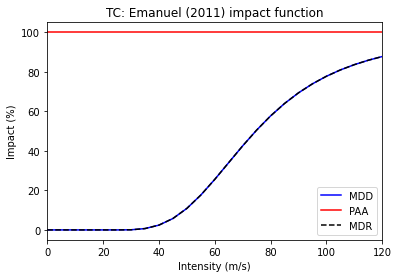
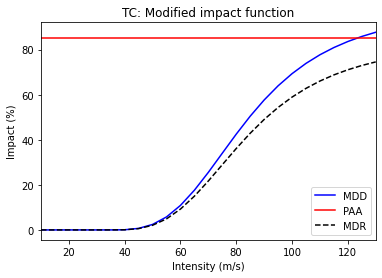
Let’s define a second measure. Again, the numbers here are made up, for illustration only.
meas_buildings = Measure(
name="Building code",
haz_type="TC",
color_rgb=np.array([0.2, 0.7, 0.5]),
cost=100000000,
hazard_freq_cutoff=0.1,
)
meas_set.append(meas_buildings)
meas_set.check()
buildings_exp, buildings_imp_fun_set, buildings_haz = meas_buildings.apply(
exp_litpop, imp_fun_set, haz
)
2022-03-21 14:38:24,711 - climada.entity.exposures.base - INFO - Matching 691 exposures with 1891 centroids.
2022-03-21 14:38:24,716 - climada.engine.impact - INFO - Calculating damage for 661 assets (>0) and 1049 events.
This measure describes an upgrade to building codes to withstand 10-year events. The measure costs 100,000,000 USD and, through hazard_freq_cutoff = 0.1, removes events with calculated impacts below the 10-year return period.
The Adaptation Measures tutorial describes other parameters for describing adaptation measures, including risk transfer, assigning measures to subsets of exposure, and reassigning impact functions.
We can compare the 5- and 20-year return period hazard (remember: not a real return period due to the small event set!) compared to the adjusted hazard once low-impact events are removed.
haz.plot_rp_intensity(return_periods=(5, 20))
buildings_haz.plot_rp_intensity(return_periods=(5, 20));
2022-03-15 22:27:56,309 - climada.hazard.base - INFO - Computing exceedance intenstiy map for return periods: [ 5 20]
2022-03-15 22:28:13,337 - climada.hazard.base - INFO - Computing exceedance intenstiy map for return periods: [ 5 20]
2022-03-15 22:28:13,911 - climada.hazard.base - WARNING - Exceedance intenstiy values below 0 are set to 0. Reason: no negative intensity values were found in hazard.
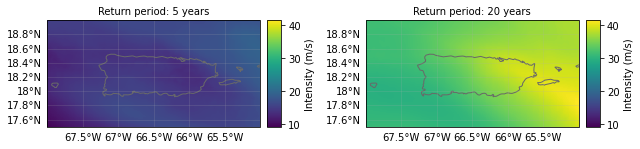
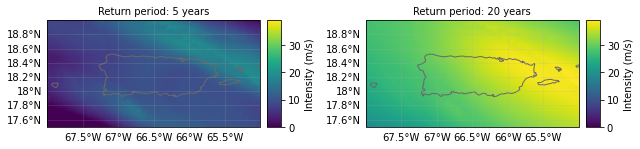
It shows there are now very few events at the 5-year return period - the new building codes removed most of these from the event set.
Discount rates#
The disc_rates attribute is of type DiscRates. This class contains the discount rates for the following years and computes the net present value for given values.
See the Discount Rates tutorial for more details about creating, reading and writing the DiscRates class, and how it is used in calculations.
Here we will implement a simple, flat 2% discount rate.
from climada.entity import DiscRates
years = np.arange(1950, 2101)
rates = np.ones(years.size) * 0.02
disc = DiscRates(years=years, rates=rates)
disc.check()
disc.plot()

We are now ready to move to the last part of the CLIMADA model for Impact and Cost Benefit analyses.
Define Entity#
We are now ready to define our Entity object that contains the exposures, impact functions, discount rates and measures.
from climada.entity import Entity
ent = Entity(
exposures=exp_litpop,
disc_rates=disc,
impact_func_set=imp_fun_set,
measure_set=meas_set,
)
Engine#
The CLIMADA Engine is where the main risk calculations are done. It contains two classes, Impact, for risk assessments, and CostBenefit, to evaluate adaptation measures.
Impact#
Let us compute the impact of historical tropical cyclones in Puerto Rico.
Our work above has given us everything we need for a risk analysis using the Impact class. By computing the impact for each historical event, the Impact class provides different risk measures, as the expected annual impact per exposure, the probable maximum impact for different return periods and the total average annual impact.
Note: the configurable parameter CONFIG.maz_matrix_size controls the maximum matrix size contained in a chunk. You can decrease its value if you are having memory issues when using the Impact’s calc method. A high value will make the computation fast, but increase the memory use.
(See the config guide on how to set configuration values.)
CLIMADA calculates impacts by providing exposures, impact functions and hazard to an Impact object’s calc method:
from climada.engine import ImpactCalc
imp = ImpactCalc(ent.exposures, ent.impact_funcs, haz).impact()
2022-03-21 14:38:36,337 - climada.engine.impact - INFO - Exposures matching centroids found in centr_TC
2022-03-21 14:38:36,343 - climada.engine.impact - INFO - Calculating damage for 661 assets (>0) and 1049 events.
A useful parameter for the calc method is save_mat. When set to True (default is False), the Impact object saves the calculated impact for each event at each point of exposure, stored as a (large) sparse matrix in the imp_mat attribute. This allows for more detailed analysis at the event level.
The Impact class includes a number of analysis tools. We can plot an exceedance frequency curve, showing us how often different damage thresholds are reached in our source data (remember this is only 40 years of storms, so not a full climatology!)
freq_curve = imp.calc_freq_curve() # impact exceedance frequency curve
freq_curve.plot()
print("Expected average annual impact: {:.3e} USD".format(imp.aai_agg))
Expected average annual impact: 9.068e+08 USD
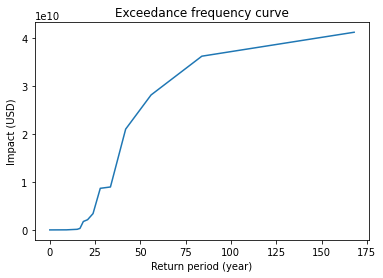
We can map the expected annual impact by exposure:
imp.plot_basemap_eai_exposure(buffer=0.1); # average annual impact at each exposure
2022-03-21 14:38:43,047 - climada.util.coordinates - INFO - Setting geometry points.
2022-03-21 14:38:43,151 - climada.entity.exposures.base - INFO - Setting latitude and longitude attributes.
2022-03-21 14:38:46,480 - climada.entity.exposures.base - INFO - Setting latitude and longitude attributes.

For additional functionality, including plotting the impacts of individual events, see the Impact tutorial.
Exercise: Plot the impacts of Hurricane Maria. To do this you’ll need to set
save_mat=Truein the earlierImpactCalc.impact().
We recommend to use CLIMADA’s writers in hdf5 or csv whenever possible. It is also possible to save our variables in pickle format using the save function and load them with load. This will save your results in the folder specified in the configuration file. The default folder is a results folder which is created in the current path (see default configuration file climada/conf/defaults.conf). The pickle format has a transient format and should be avoided when possible.
import os
from climada.util import save, load
### Uncomment this to save - saves by default to ./results/
# save('impact_puerto_rico_tc.p', imp)
### Uncomment this to read the saved data:
# abs_path = os.path.join(os.getcwd(), 'results/impact_puerto_rico_tc.p')
# data = load(abs_path)
Impact also has write_csv() and write_excel() methods to save the impact variables, and write_sparse_csr() to save the impact matrix (impact per event and exposure). Use the Impact tutorial to get more information about these functions and the class in general.
Adaptation options appraisal#
Finally, let’s look at a cost-benefit analysis. The adaptation measures defined with our Entity can be valued by estimating their cost-benefit ratio. This is done in the class CostBenefit.
Let us suppose that the socioeconomic and climatoligical conditions remain the same in 2040. We then compute the cost and benefit of every adaptation measure from our Hazard and Entity (and plot them) as follows:
from climada.engine import CostBenefit
cost_ben = CostBenefit()
cost_ben.calc(haz, ent, future_year=2040) # prints costs and benefits
cost_ben.plot_cost_benefit()
# plot cost benefit ratio and averted damage of every exposure
cost_ben.plot_event_view(
return_per=(10, 20, 40)
); # plot averted damage of each measure for every return period
2022-03-15 22:32:07,393 - climada.engine.impact - INFO - Exposures matching centroids found in centr_TC
2022-03-15 22:32:07,397 - climada.engine.impact - INFO - Calculating damage for 691 assets (>0) and 1040 events.
2022-03-15 22:32:07,406 - climada.engine.impact - INFO - Exposures matching centroids found in centr_TC
2022-03-15 22:32:07,408 - climada.engine.impact - INFO - Calculating damage for 691 assets (>0) and 1040 events.
2022-03-15 22:32:07,418 - climada.engine.impact - INFO - Exposures matching centroids found in centr_TC
2022-03-15 22:32:07,420 - climada.engine.impact - INFO - Calculating damage for 691 assets (>0) and 1040 events.
2022-03-15 22:32:07,437 - climada.engine.impact - INFO - Exposures matching centroids found in centr_TC
2022-03-15 22:32:07,440 - climada.engine.impact - INFO - Calculating damage for 691 assets (>0) and 1040 events.
2022-03-15 22:32:07,452 - climada.engine.cost_benefit - INFO - Computing cost benefit from years 2018 to 2040.
Measure Cost (USD bn) Benefit (USD bn) Benefit/Cost
------------- --------------- ------------------ --------------
Mangrove 0.5 11.2129 22.4258
Building code 0.1 0.00761204 0.0761204
-------------------- --------- --------
Total climate risk: 17.749 (USD bn)
Average annual risk: 0.951281 (USD bn)
Residual risk: 6.52855 (USD bn)
-------------------- --------- --------
Net Present Values
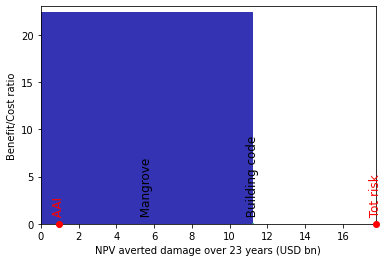
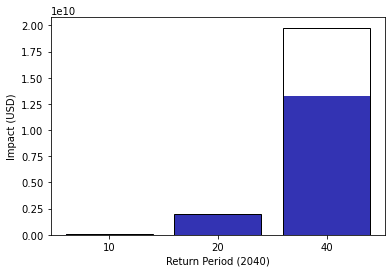
This is just the start. Analyses improve as we add more adaptation measures into the mix.
Cost-benefit calculations can also include
climate change, by specifying the
haz_futureparameter inCostBenefit.calc()changes to economic exposure over time (or to whatever exposure you’re modelling) by specifying the
ent_futureparameter inCostBenefit.calc()different functions to calculate risk benefits. These are specified in
CostBenefit.calc()and by default use changes to average annual impactlinear, sublinear and superlinear evolution of impacts between the present and future, specified in the
imp_time_depenparameter inCostBenefit.calc()
And once future hazards and exposures are defined, we can express changes to impacts over time as waterfall diagrams. See the CostBenefit class for more details.
Exercise: repeat the above analysis, creating future climate hazards (see the first exercise), and future exposures based on projected economic growth. Visualise it with the
CostBenefit.plot_waterfall()method.
What next?#
Thanks for following this tutorial! Take time to work on the exercises it suggested, or design your own risk analysis for your own topic. More detailed tutorials for individual classes were listed in the Features section.
Also, explore the full CLIMADA documentation and additional resources described at the start of this document to learn more about CLIMADA, its structure, its existing applications and how you can contribute.